

使用 PHP 编写的从云湖网页获取用户、群聊、机器人详细信息的 API。
开发背景
云湖的很多设计都是半成品,比如很难查询自己的注册时间、在加群/机器人之前无法查询群/机器人信息等问题。
为了方便查询这些信息,于是开发此 API。
开发过程
云湖的网页(https://www.yhchat.com/[type]/homepage/[id])采用了 nuxt 开发,返回的 html 内容中直接包含了数据:
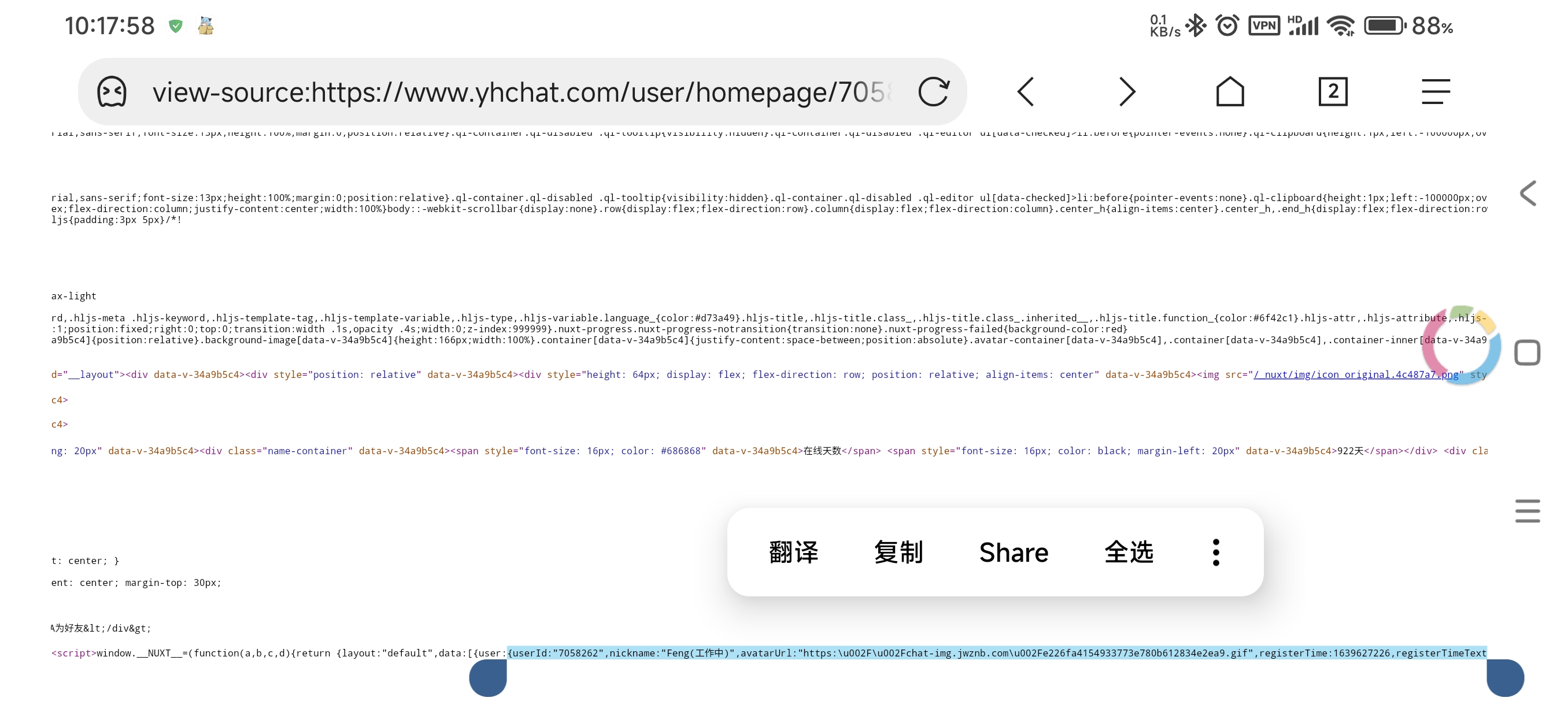
V1
于是第一版的 API 直接开发出来:直接通过 cURL 请求指定链接,通过特征判断该 ID 是否存在,然后使用正则表达式直接提取相应内容。
虽然使用正则表达式麻烦了一点,但是用还是能用的。
然后,我就发现这返回的数据里还有变量!
还记得 window.__NUXT__=(function(a,b,c,d)里的 a,b,c,d 吗?那玩意是变量,在后面的数据中会调用!
当时没有其他办法,只能使用一些奇淫技巧来避开这些变量(具体用了什么方法自行翻 V1 分支的源码,包括但不限于从 html 标签而非 script 中提取、反向判断、放弃此参数不要了等等)。
V2
仔细观察 script 部分返回的内容,前面是 window.__NUXT__=(function(a,b,c,d),定义了变量 a,b,c,d,中间是数据部分,而后面的 ("",1,"内测用户",null));不正好对应了前面的变量吗?
况且,注意到中间的数据部分非常像 JSON,那直接把中间部分提取出来,然后把变量还原回去不就行了吗?
但没想到,想着简单,做起来却是一波三折。
下面给出每个部分的代码和详解。
匹配script 部分
这个简单,直接使用正则表达式 /<script>window\.__NUXT__=\((.*?)\);<\/script>/匹配即可。
输出如下:
function(a,b,c,d){return {layout:"default",data:[{user:{userId:"7058262",nickname:"Feng(工作中)",avatarUrl:"https:\u002F\u002Fchat-img.jwznb.com\u002Fe226fa4154933773e780b612834e2ea9.gif",registerTime:1639627226,registerTimeText:"2021-12-16 12:00:26",onLineDay:922,continuousOnLineDay:9,medals:[{id:b,name:c,desc:c,imageUrl:a,sort:100},{id:4,name:"1000用户",desc:a,imageUrl:a,sort:300},{id:5,name:"10000用户",desc:a,imageUrl:a,sort:400}],isVip:b}}],fetch:{},error:d,state:{app:{isMobile:"222222"},user:{token:a,name:a,avatar:a,welcome:a,roles:[],info:{}}},serverRendered:true,routePath:"\u002Fuser\u002Fhomepage\u002F7058262",config:{_app:{basePath:"\u002F",assetsPath:"\u002F_nuxt\u002F",cdnURL:d}}}}("",1,"内测用户",null)
匹配变量名
观察到变量名是夹在 function(和 ){return {中间的,使用 ,分割,于是使用 /function\((.*?)\)/匹配并按 ,分割为数组。
输出如下:
a,b,c,d
Array
(
[0] => a
[1] => b
[2] => c
[3] => d
)
匹配变量值
同理,观察到变量值是夹在 }}(和 )中间的,使用 ,分割,于是使用 /}}\((.*?)\)/匹配并按 ,分割为数组。
输出如下:
"",1,"内测用户",null
Array
(
[0] => ""
[1] => 1
[2] => "内测用户"
[3] => null
)
匹配主体信息
主体信息是夹在 user:(这里的 user要根据目标类型替换成 group或 bot和 }],fetch:{}中间的,于是使用 /user:(.*?)}],fetch/匹配即可。
输出如下:
{userId:"7058262",nickname:"Feng(工作中)",avatarUrl:"https:\u002F\u002Fchat-img.jwznb.com\u002Fe226fa4154933773e780b612834e2ea9.gif",registerTime:1639627226,registerTimeText:"2021-12-16 12:00:26",onLineDay:922,continuousOnLineDay:9,medals:[{id:b,name:c,desc:c,imageUrl:a,sort:100},{id:4,name:"1000用户",desc:a,imageUrl:a,sort:300},{id:5,name:"10000用户",desc:a,imageUrl:a,sort:400}],isVip:b}
还原 UTF-8 编码
观察到返回的信息中 URL都是使用 UTF-8 编码的,如 https:\u002F\u002Fchat-img.jwznb.com\u,这里就需要还原。
下面的代码是由 AI 给的。
$info = preg_replace_callback('/\\\\u([0-9a-fA-F]{4})/', function ($matches) {
return mb_convert_encoding(pack('H*', $matches[1]), 'UTF-8', 'UCS-2BE');
}, $content[1]);
还原变量
下面的代码基本上也是 AI 给的😂
2024.11.25 更新:
之前的代码有单个字母a,b,c,d被当成键名被替换的问题,更新之后的代码:
foreach ($params as $key => $value) {
// 替换时,使用 JSON 编码的值,防止误匹配
$value = json_encode(trim($value, '"'));
$info = preg_replace('/\b' . preg_quote($key, '/') . '\b(?=[:,}])/', $value, $info);
}
之前的代码:
// 创建关联数组
$params = array_combine($param_names, $param_values);
// 全词匹配
foreach ($params as $key => $value) {
$info = preg_replace('/\b' . preg_quote($key, '/') . '\b/', $value, $info);
}
输出如下:
{userId:"7058262",nickname:"Feng(工作中)",avatarUrl:"https://chat-img.jwznb.com/e226fa4154933773e780b612834e2ea9.gif",registerTime:1639627226,registerTimeText:"2021-12-16 12:00:26",onLineDay:922,continuousOnLineDay:9,medals:[{id:1,name:"内测用户",desc:"内测用户",imageUrl:"",sort:100},{id:4,name:"1000用户",desc:"",imageUrl:"",sort:300},{id:5,name:"10000用户",desc:"",imageUrl:"",sort:400}],isVip:1}
修复 JSON 键值
这个时候我非常激动,这不就是个 JSON 吗!直接解析!不出意外,失败了。我看了很久,才发现它并不是标准的 JSON 合适,键值没有引号。
我和 Copilot, GPT-3.5 等 AI 说了很久,试了无数正则表达式,但是不管怎么样不是处理不好时间中的冒号,就是处理不好 URL 中的冒号。
比如:
$info = preg_replace_callback('/([a-zA-Z0-9_]+):/', function ($matches) {
return '"' . $matches[1] . '":';
}, $info);
输出为:
{"userId":"7058262","nickname":"Feng(工作中)","avatarUrl":""https"://chat-img.jwznb.com/e226fa4154933773e780b612834e2ea9.gif","registerTime":1639627226,"registerTimeText":"2021-12-16 "12":"00":26","onLineDay":922,"continuousOnLineDay":9,"medals":[{"id":1,"name":"内测用户","desc":"内测用户","imageUrl":"","sort":100},{"id":4,"name":"1000用户","desc":"","imageUrl":"","sort":300},{"id":5,"name":"10000用户","desc":"","imageUrl":"","sort":400}],"isVip":1}
比如:
$info = preg_replace('/([a-zA-Z_][a-zA-Z0-9_]*):/', '"$1":', $info);
输出为:
{"userId":"7058262","nickname":"Feng(工作中)","avatarUrl":""https"://chat-img.jwznb.com/e226fa4154933773e780b612834e2ea9.gif","registerTime":1639627226,"registerTimeText":"2021-12-16 12:00:26","onLineDay":922,"continuousOnLineDay":9,"medals":[{"id":1,"name":"内测用户","desc":"内测用户","imageUrl":"","sort":100},{"id":4,"name":"1000用户","desc":"","imageUrl":"","sort":300},{"id":5,"name":"10000用户","desc":"","imageUrl":"","sort":400}],"isVip":1}
比如:
$info = preg_replace('/(?<!")([a-zA-Z_][a-zA-Z0-9_]*)(?=\s*:)/', '"$1"', $info);
输出为:
{"userId":"7058262","nickname":"Feng(工作中)","avatarUrl":"h"ttps"://chat-img.jwznb.com/e226fa4154933773e780b612834e2ea9.gif","registerTime":1639627226,"registerTimeText":"2021-12-16 12:00:26","onLineDay":922,"continuousOnLineDay":9,"medals":[{"id":1,"name":"内测用户","desc":"内测用户","imageUrl":"","sort":100},{"id":4,"name":"1000用户","desc":"","imageUrl":"","sort":300},{"id":5,"name":"10000用户","desc":"","imageUrl":"","sort":400}],"isVip":1}
于是这个项目也被搁置了一段时间。
直到最近我想起还有 GPT-4o,起先它也犯了一样的错误,但在经过数次交谈,反复修改之后,它终于给出了正确的正则表达式!
preg_replace('/(?<=\{|\[|\,)(\s*)([a-zA-Z_][a-zA-Z0-9_]*)(?=\s*:)/', '$1"$2"', $info);
输出就是正常的 JSON 了:
{"userId":"7058262","nickname":"Feng(工作中)","avatarUrl":"https://chat-img.jwznb.com/e226fa4154933773e780b612834e2ea9.gif","registerTime":1639627226,"registerTimeText":"2021-12-16 12:00:26","onLineDay":922,"continuousOnLineDay":9,"medals":[{"id":1,"name":"内测用户","desc":"内测用户","imageUrl":"","sort":100},{"id":4,"name":"1000用户","desc":"","imageUrl":"","sort":300},{"id":5,"name":"10000用户","desc":"","imageUrl":"","sort":400}],"isVip":1}
具体对话过程可以去看:https://chatgpt.com/share/67429a2d-a8b0-800d-ae71-31124b172d2d
ID 不存在判断
由于 NUXT 在面对 ID 不存在的时候也会返回数据,所以需要自己手动判断一下这个 ID 是否存在。我是采用检测网页中是否存在关键词。当 ID 不存在时网页是这样的: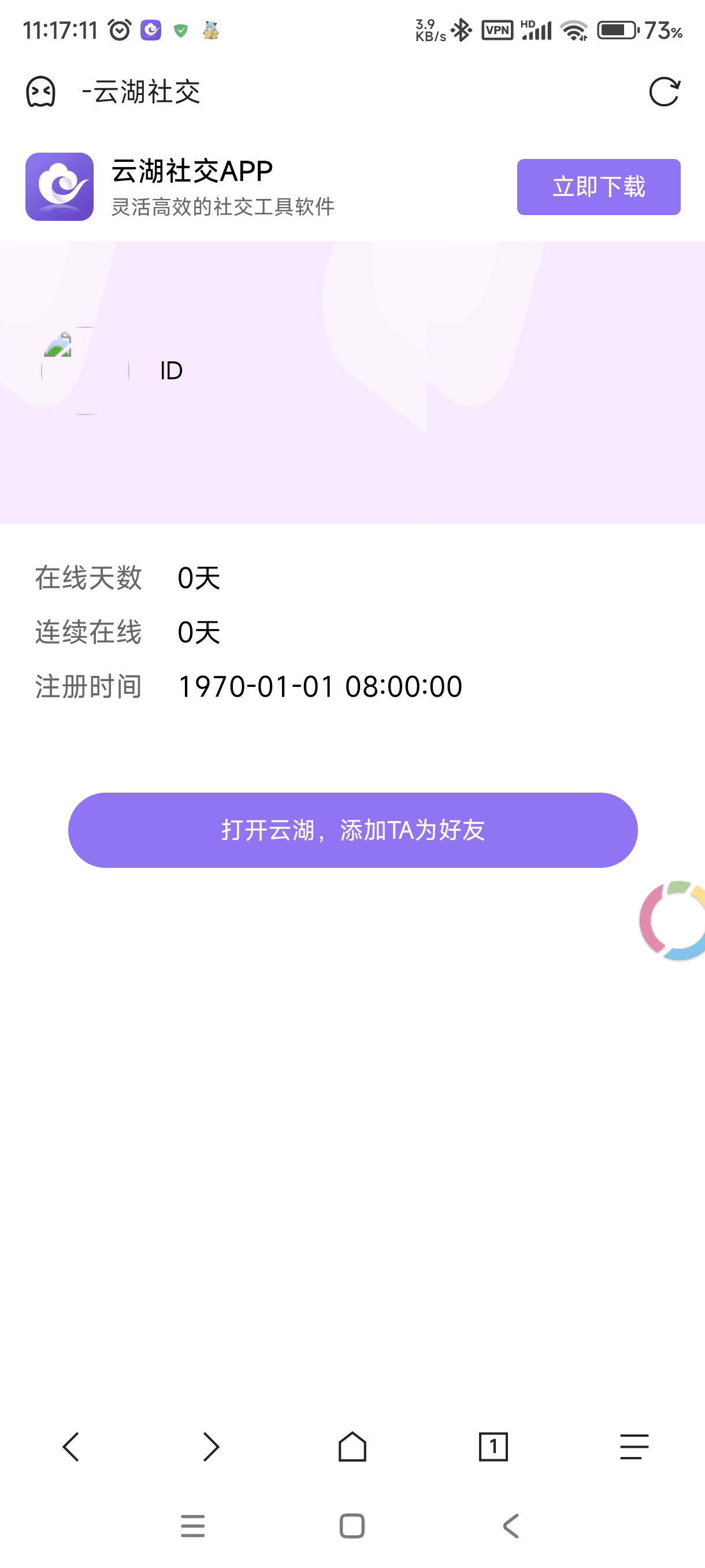
此时有一个 span 显示了空的 ID: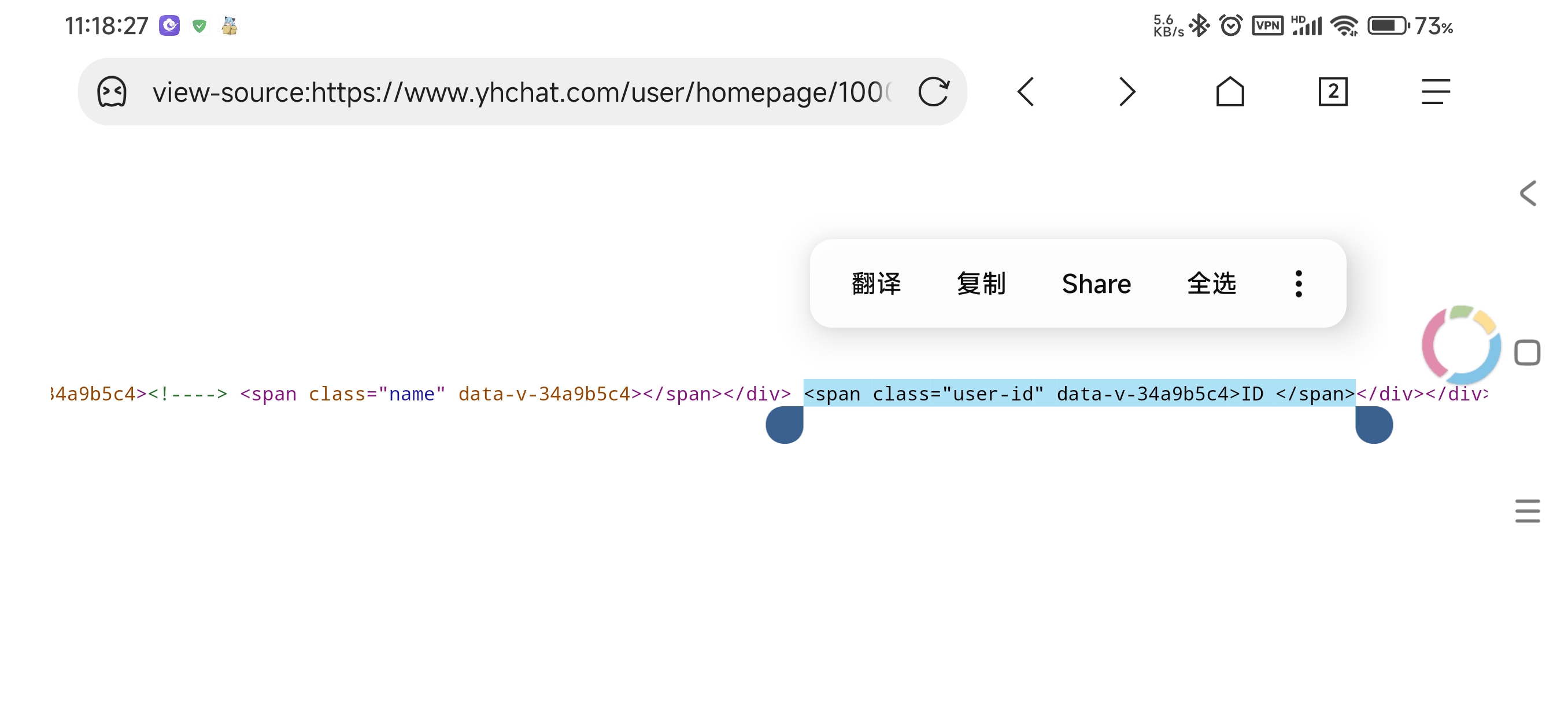 直接检测它就可以了。
直接检测它就可以了。
用户检测 data-v-34a9b5c4>ID </span>,群聊检测 data-v-6eef215f>ID </span>,机器人检测 data-v-4f86f6dc>ID </span>
使用方法
自行部署
API 的源码和文档都在 Github:https://github.com/jibukeshi/yunhu_info_api
机器人查询
我已经把这个功能加到了我的机器人中,输入 ID 即可直接查询。
访问链接使用云湖机器人【轻智小助手云湖版】
https://yhfx.jwznb.com/share?key=X7ihZbOM9YcK&ts=1712137543
机器人ID: 43272366
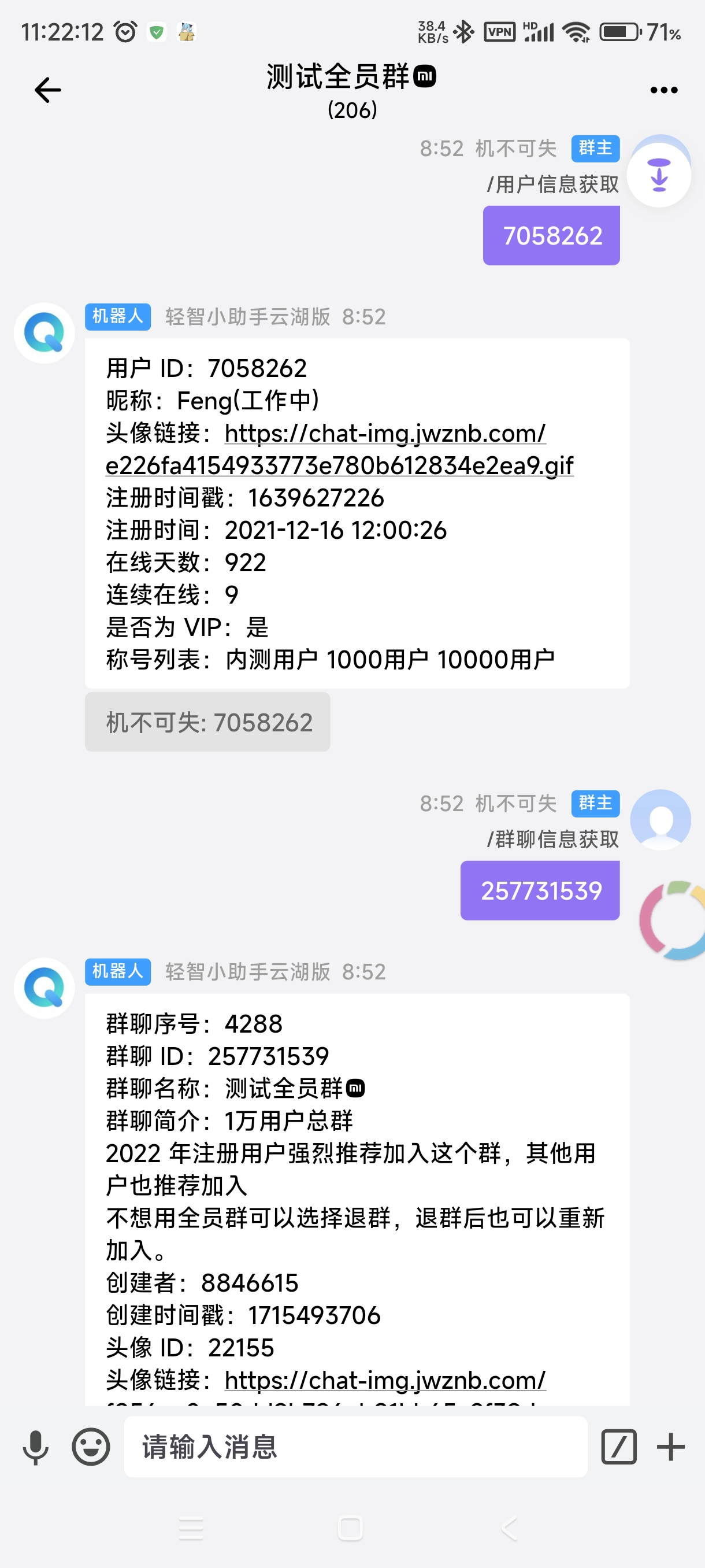
演示调用
请求 https://qingzhi.jibukeshi.us.kg/api/yunhu/api.php,按照文档中所说调用即可。
评论区